Project POLY: Personal Intelligence
Meet POLY.


POLY is my private AI system. It runs on my computer, will never touch the internet, and is grounded in two very important corpora:
The Civilization Library. Roughly 3,000 professional-grade textbooks across every major domain of modern human knowledge. 1.5 billion words spread across 1,132 distinct domains of the highest-signal material I could find anywhere on earth.
10 million words of my life data. Years of notes, writing, chat logs, and everything I have ever produced that captures how I actually reason.
POLY sits as a grounding layer underneath the frontier models. When I hit a hard question or a new domain, I start with whichever frontier model is strongest for that specific problem and ask it via voice. Then I carry what I learn to the next one, moving back and forth between Claude, Gemini, ChatGPT, and Grok, each chosen for what it does best, until I have a real grasp of the problem. The routing is my own judgment and not a pipeline. Once I understand the shape of it, I take everything I've learned into POLY and go deeper, grounding it against the full Civilization Library for textbook-grade depth and against my life data so the answer is calibrated to how I already think. It’s the closest thing I have to a complete polymath learning loop.
The result is cross-domain synthesis at a depth and speed that did not exist a year ago. Neither did most of the tools behind it.
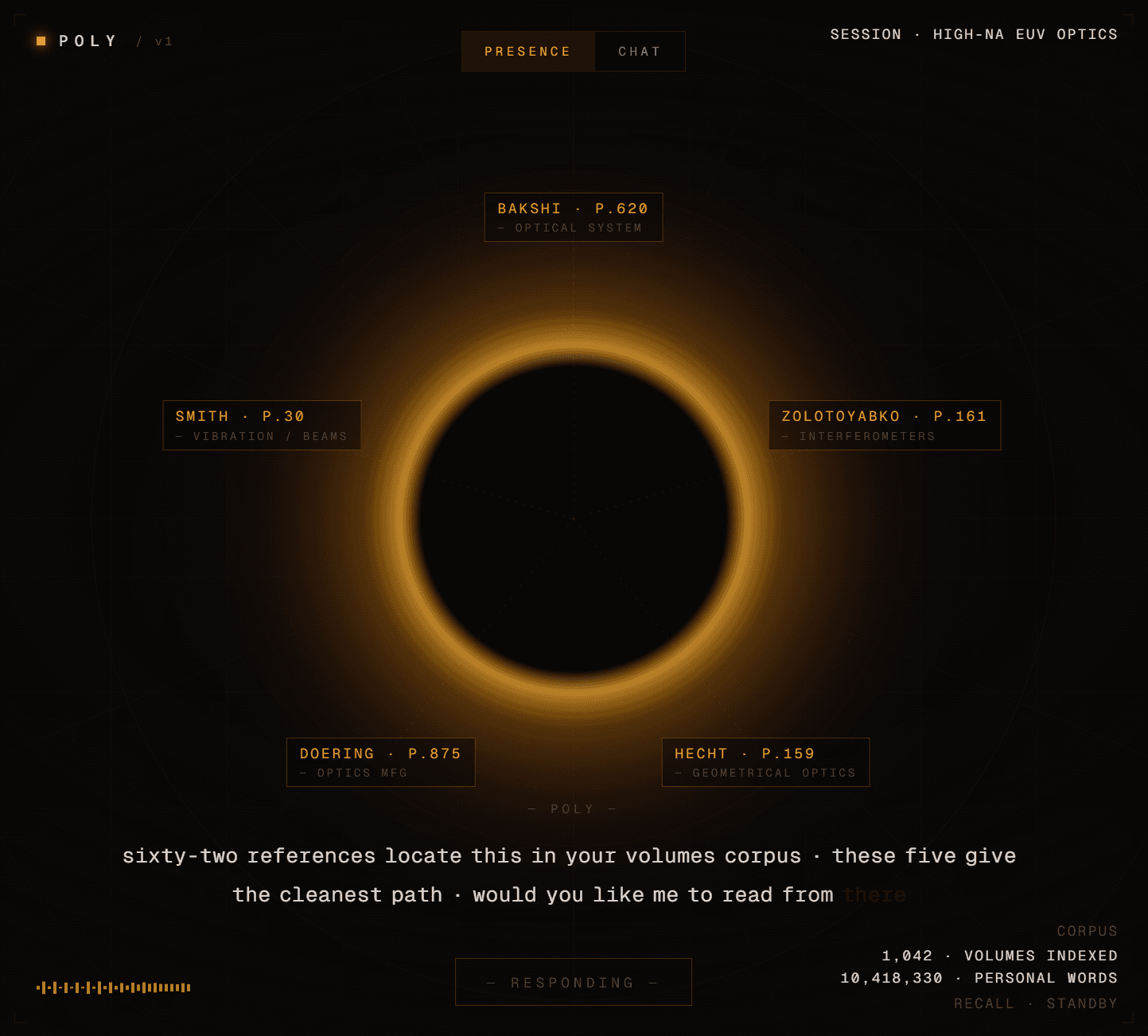
The reason POLY exists as a grounding layer underneath the frontier models is simple. Frontier models have read about most of the textbooks in my Civilization Library, but they have not absorbed the textbooks themselves. Frontier models are trained on trillions of words of internet text, which is mostly humans talking about these textbooks. Some of the actual pages are in there somewhere, but even when a model has seen the text, it cannot reliably reproduce a specific page on demand. Ask Claude or ChatGPT what Griffiths says about Gauss's law on page 72 and you get a confident paraphrase that may or may not be accurate. Ask POLY and you get the actual page.
By itself, POLY is an idiot. A quantized Gemma 4 variant running on my RTX 3090 with two local RAG databases on a custom-built architecture. POLY itself costs me nothing to run. It never leaves the machine and is completely air-gapped.
I know someone will probably call this a RAG wrapper. They are technically right. The inference layer is an open-source model. I did not build that part and I'm not claiming to have built that part. What I built is the 3,000 textbook knowledge base, the ten million words of life data, and the architecture that sits above it all. That's the part I spent months building. Fine-tuning an AI model on this content would produce a model that sounds like a textbook and hallucinates citations, which is the opposite of what I need. Eventually I'll train a personal model from scratch when the compute cost collapses.
POLY started as a moodboard in Figma. I needed something simple that wasn't distracting or a terminal, because I'll be staring at it for hours at a time working through hard material. I designed the full interface there, prototyped it in Claude Design until the interaction felt right, then ran every screen through the same manual, model-by-model loop I run before POLY. Claude, Gemini, ChatGPT, and Grok each tore the design apart, and I reconciled the sharpest critiques by hand. The interface is the output of that loop.
The backend was the hard part. No single RAG framework did what I needed inside the memory ceiling of one consumer GPU, so I built my own. I stitched several open-source repositories and retrieval architectures into a single system tuned to run entirely on a single RTX 3090 with 32 GB of RAM. Most off-the-shelf RAG assumes cloud-scale resources. Mine assumes one machine and a hard constraint. Right now it cleanly indexes 1,042 of the roughly 3,000 volumes, and getting the full corpus online without breaking retrieval is exactly the optimization work I'm still doing.
But none of that was the real work. The real work was curation. The overwhelming majority of those three months went into assembling, verifying, and structuring the knowledge base itself, because a retrieval system is only as good as what it retrieves.
Stacked under four frontier models and indexed against thousands of textbooks and a decade of my own thinking, POLY is one of the most useful instruments I have ever built.
I won't be releasing POLY publicly. POLY will remain a private tool. I will, however, open source the methodology so anyone can build their own version of POLY using their knowledge base and life data. It will be incredibly simple to set up and eventually work on any device. I'll publish this as soon as I finish the RAG architecture optimization. The Civilization Library itself is published as a list of titles for anyone who wants to build their own version.
The category of personal intelligence is coming fast. Memory orchestration is quietly becoming the most important unsolved problem in consumer AI: getting a system to store, retrieve, and surface the right parts of your history, preferences, and knowledge at the right moment. Andrej Karpathy has pointed in this direction with LLM Wiki, and Garry Tan is actively building in a similar direction with GBrain. Agents like Hermes and OpenClaw already retain what you prefer over time. Quantization and edge compute keep collapsing the cost curve. All of it points in the same direction: personal AI grounded in your own life data and your own knowledge base, running locally on consumer hardware.
The next phase is systems that build real world models instead of only predicting the next token. The big labs are moving here, and it's the center of my own AI and cognition research. When those land, POLY gets a brain transplant and the synthesis jumps another order of magnitude.
If you want to start building toward this yourself, do two things now:
Gather your life data. Chat logs, writing, notes, anything that captures how you actually think. Export it. Clean it. Store it somewhere you control.
Curate your knowledge base. For whatever you are trying to master, assemble the textbook-grade references experts actually use.
When building personal models on consumer hardware goes trivially cheap, which is coming faster than most people expect, the people who already have clean life data and a high-signal knowledge base are the ones who get the head start.
I built POLY so I can learn ten times faster than I was already learning. This is what personal intelligence looks like.
Excited to see how far it takes me.
-------------------------------------------------
Everything above this line is the original announcement. Project POLY is a working system I use every day and will keep building on. Everything below is the reverse-chronological log of how it evolves. I will update this page regularly as I execute new model swaps, refine the RAG architecture, and use POLY to accelerate my own cross-domain research.
Future milestone: POLY V2 — the research frontier. In my polymath thesis, I argue that breakthroughs live in the connections between fields. Those connections do not live in textbook consensus. They live at the research frontier, where fields are actively working and actively disagreeing. The Civilization Library grounds POLY in what is known. V2 will ground POLY in what is being worked on. This means adding a curated corpus of foundational and recent research papers from arXiv and adjacent sources, organized by field and citation weight. V1 is a learning instrument: what's known? V2 becomes a research instrument: what's being worked on, where are the open problems, and where do fields disagree? That is where the actual contribution lives.
Last updated: June 2, 2026